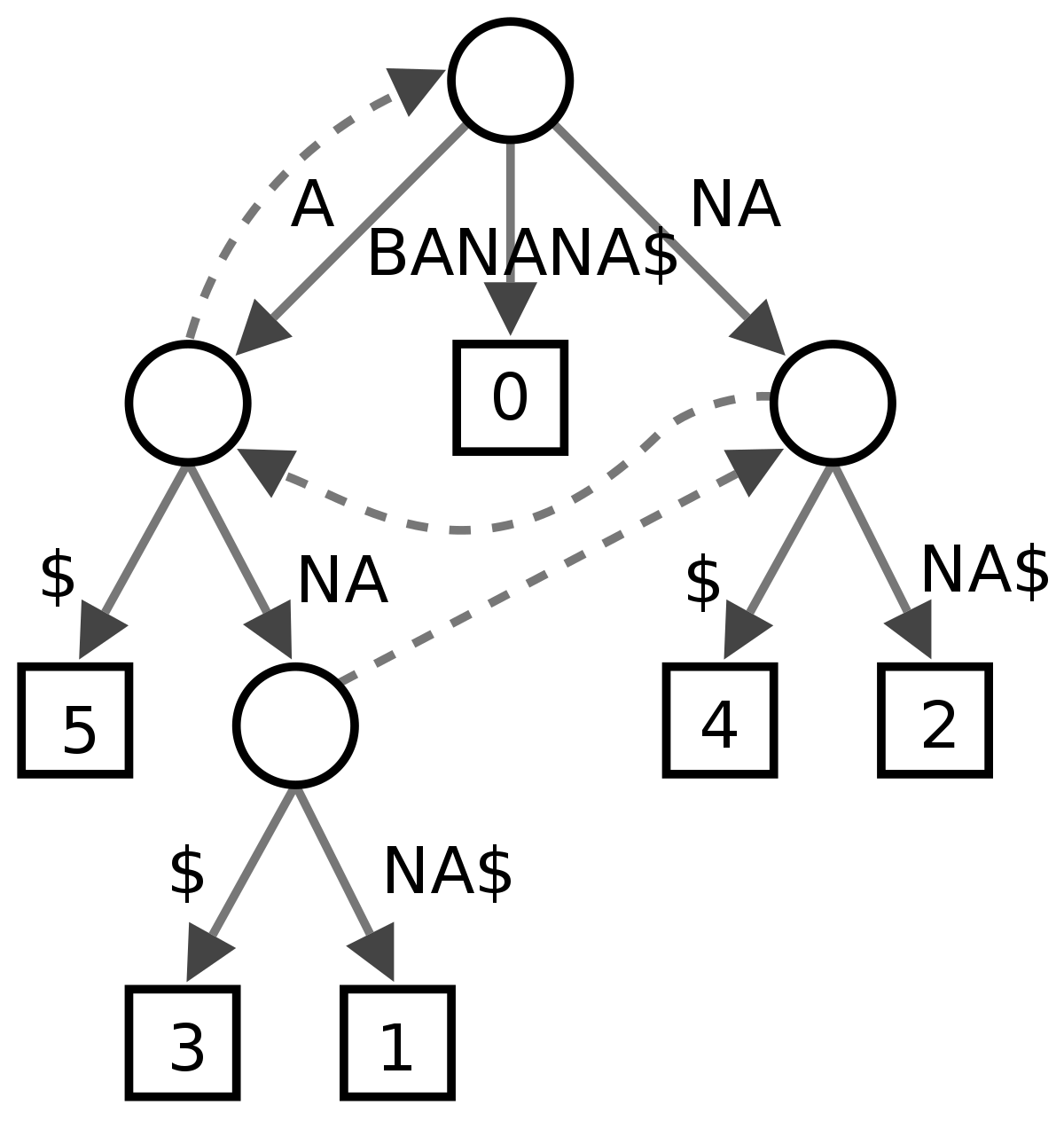
מובן, שאם יש שתי מילים באורך זהה, מספיק שאות אחת בלבד תהיה שונה.
אז נחזיק מילון שבו המפתח תהיה האות, והערך יהיה גם הוא מילון – בו המפתח יהיה אורך המחרוזת, והערך – מערך של כל המחרוזות שמתחילות באותה אות.
ירושלים, חלום, שלום, מספר, ספר, ים, לו.
נתחיל עם המחרוזת הארוכה ביותר, ונלך למקום של התו הראשון של המחרוזת במילון – נניח, עבור המחרוזת 'ירושלים' – נלך לאות י'. באותה אות, נראה אם נמצאו מחרוזות באורך זהה או גדול לאורך המחרוזת הנוכחית. לא נמצא? מצוין, המחרוזת אינה קיימת. נוסיף אותה למערך התוצאה ונפרק אותה – י': 7: ירושלים, ר': 6: רושלים, ו':5: ושלים וכן הלאה.
כשלא מצאנו התאמה לאות הראשונה, אפשר להפסיק. אם נמצאה התאמה באות הראשונה, אבל לא בהמשך המחרוזת, יש להמשיך בתהליך (נניח, יש לנו גם את המילה ,ירושליא).
בכל פעם שמורידים אות, הולכים למקום המתאים במילון – ובודקים רק מול המילים באותו אורך.
את חיפוש ההתאמה של המחרוזת או תת המחרוזת אפשר למקבל (נניח, באות א' באורך 5 יש 30 מילים – אפשר להשוות לכולן במקביל)
וכמו כן - אפשר לחפש התאמה במקביל לכל המילים באותו האורך שמתחילות בתווים שונים.
 הנושאים החמים
הנושאים החמים
 הנושאים החמים
הנושאים החמים
") ) כי קצת קשה לדון בנושא הזה על האצבעות.
) כי קצת קשה לדון בנושא הזה על האצבעות.